- Published on
Universal binaries for Stockfish
- Authors

- Name
- Timothy Herchen
I've been working for the past few months on so-called "universal binaries" for the chess engine Stockfish. As my first serious foray into linkers and executable formats, it was a bumpy ride, but I'm quite proud of the end result!
The problem
Stockfish is carefully optimized for many different machine architectures. Throughout the code, and especially in the neural network inference, there are specific code paths for SSE, AVX2, AVX-512, Neon, and (very recently) Loongarch64.
The performance delta between binaries can be quite large. As an extreme example, on my Zen 5 machine, the x86-64 baseline build – compatible with all 64-bit x86 machines, i.e., every computer made by Intel or AMD in the past 20 years – is 61% slower than the preferred x86-64-avx512icl build. On most computers, however, the avx512icl build would immediately crash. There is a fundamental tension between a binary which is broadly compatible with people's systems and one which provides peak performance on a particular person's system.
Our longstanding approach was to distribute many binaries and trust the end user to select the ideal one for their system. But most users don't know what their hardware is capable of (quite reasonably – this is esoteric stuff!), so in practice we would advertise a build likely to work on most systems, followed by the rest of the builds, for techies with recent hardware or folks stuck with older systems.1
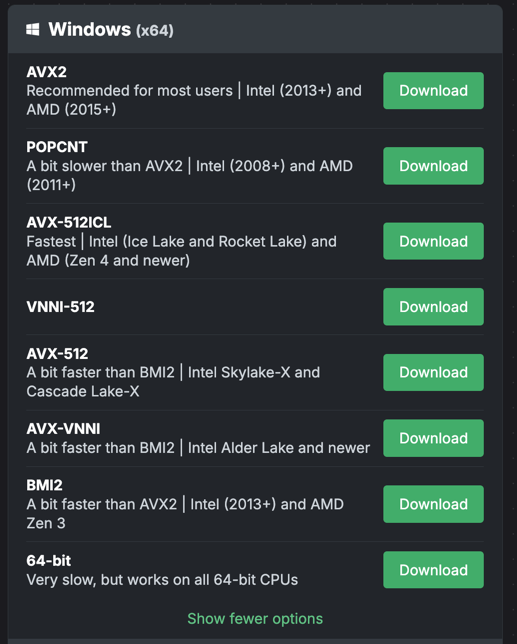
The problem also affects app distributors, who may want to distribute builds that are compatible even with very old systems. While they could conceivably detect and ship the best binary, this requires a lot of bespoke effort.
My goal was to construct a single artifact which at startup would detect the abilities of the CPU, then select and use the codepath best for that CPU. Users downloading the binaries from our website wouldn't need to make a confusing choice, and downstream distributors could ship a binary that would run optimally on all machines.
Discarded solutions
Ship all the binaries, pick one
A brutish solution is to pack all the binaries, then bootstrap on the first startup by detecting the best arch and exporting it as an executable (say, by rewriting the bootstrap binary in place). One superficial issue is the bloat of downloading many copies of Stockfish – but this is mitigated by storing only one copy of the neural network weights, which comprise 95% of the binary. A more intractable issue is that this requires write access to the filesystem, which would be blocked in many settings.
Ship all the binaries, map one as executable memory
A slight refinement of this idea is to create an executable region (via mmap or VirtualAlloc) and write code into that region. This would work in some settings, but creating RWX regions isn't always permitted (on iOS, for example). A more subtle issue impacts the common use case of simultaneously running many copies of the engine, say, when doing bulk analysis of positions. With a standard executable the OS shares a single physical copy of the code in memory between the processes, allowing better use of the instruction cache. Manually mapping executable regions defeats this optimization.
Dynamic dispatch
GCC and clang support function multi-versioning (FMV), which lets you optimize a specific function for different targets; the dynamic loader selects the right one at runtime:
__attribute__((target("default")))
int foo() {
// The default version of foo.
return 0;
}
__attribute__((target("avx2")))
int foo() {
__m256i v; // can use avx2 features here
return 1;
}
FMV works well for projects that have specific hot functions to be optimized, but Stockfish's performance profile is pretty flat, plus relies on aggressive inlining. FMV would also require substantial changes to the code, which is a no-go; we wanted the existence of universal binaries to have no impact on day-to-day Stockfish development.
The proposed solution
We evidently needed an ordinary executable with multiple, functionally independent Stockfish implementations sharing only one copy of the NN weights, and an entry point to select one. We'd build multiple copies of Stockfish, each one with a different architecture specified. We'd then take each build's object files, and perform a final link with an additional, special main function that performs the selection.
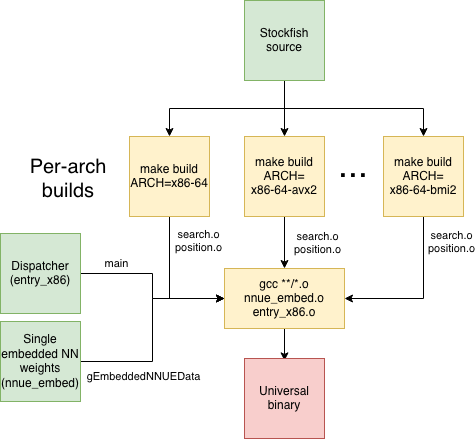
This architecture is straightforward enough at a high level, but – of course – the devil's in the details.
Resolving symbol collisions
If you just try to link multiple copies of Stockfish, you'll immediately hit duplicate symbol errors. Indeed, across the myriad object files there are multiple copies of functions like Stockfish::Position::do_move, each one optimized for a different architecture. And of course, there's multiple main functions!
Thankfully, Stockfish devs are fastidious about namespacing everything, so we can redefine the Stockfish namespace to (for example) Stockfish_x86_64_avx2 using the preprocessor. The only non-namespaced symbols are main and the neural network weights, which both need special handling anyway. For the universal binary only, we place main in the same namespace as everything else:
using namespace Stockfish;
#ifdef UNIVERSAL_BINARY
namespace Stockfish {
int main(int argc, char* argv[]); // silence 'no previous declaration'
__attribute__((used)) // keep main alive
#endif
int main(int argc, char* argv[]) {
std::cout << engine_info() << std::endl;
Bitboards::init();
Attacks::init();
Position::init();
auto uci = std::make_unique<UCIEngine>(argc, argv);
Tune::init(uci->engine_options());
uci->loop();
return 0;
}
#ifdef UNIVERSAL_BINARY
} // namespace Stockfish
#endif
(Remember that Stockfish will be renamed by the preprocessor to a per-arch name.) In a standard build, main is main. In a universal binary, Stockfish_x86_64_avx2::main is now the AVX2 entry point, and main is the dispatcher.
Embedding the neural network
To embed the neural network, Stockfish by default uses the incbin.h library, which uses a variety of platform-specific assembly directives to embed files as arrays. Unfortunately, these directives are opaque to the compiler and linker, so we have no easy way of de-duping them.
C23/C++26 added the #embed preprocessor directive, which is an easy workaround. We supply a universal binary–only, platform-agnostic nnue_embed.cpp:
extern const unsigned char gEmbeddedNNUEData[] =
#ifdef __has_embed
{
#embed EvalFileDefaultName
};
const unsigned int padding = 0;
#else
#include "network_dump.inc"
;
const unsigned int padding = 1; // trailing NUL byte
#endif
extern const unsigned int gEmbeddedNNUESize = sizeof(gEmbeddedNNUEData) - padding;
(As a fallback for older compilers, we embed the file as a string literal in network_dump.inc.2) These symbols are named identically to the incbin.h-generated symbols but can be de-duplicated in the final link.
The global entry point
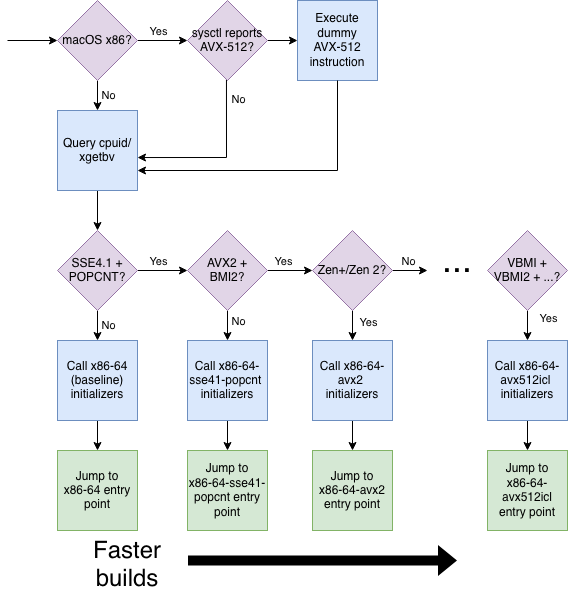
Having compiled a bunch of arch-specific entry points – Stockfish_x86_64_avx2::main, Stockfish_x86_64_bmi2::main, and so on – we now face the same conundrum that our users had: which one do we use?
x86 kindly supplies the cpuid and xgetbv instructions which tell us whether the CPU and the OS, respectively, support particular ISA extensions or architectural state. My original global entry point parsed these bits directly, but Disservin noticed that we could use the (x86-only) __builtin_cpu_init/__builtin_cpu_is/__builtin_cpu_supports, supported by both GCC and clang, which use the standard instructions under the hood. This is much cleaner.
ARM requires OS-specific code (getauxval(AT_HWCAP) on Linux and IsProcessorFeaturePresent on Windows). We currently only have two ARM builds (armv8, armv8-dotprod), so the code is pretty short. If we ever decide to adopt SVE3 or other extensions, then of course we'd have to expand this.
Dealing with static initializers
When we compile, say, the AVX-512 build, the compiler will generate code to initialize global variables. These static initializers run even before we get to main, and so will be run regardless of the architecture. To make things worse, they may contain AVX-512 instructions, even if we don't explicitly use AVX-512 intrinsics, because we allowed it in the build flags! In practice, before we even get to main on AVX2 machines, we crash upon executing an illegal instruction:
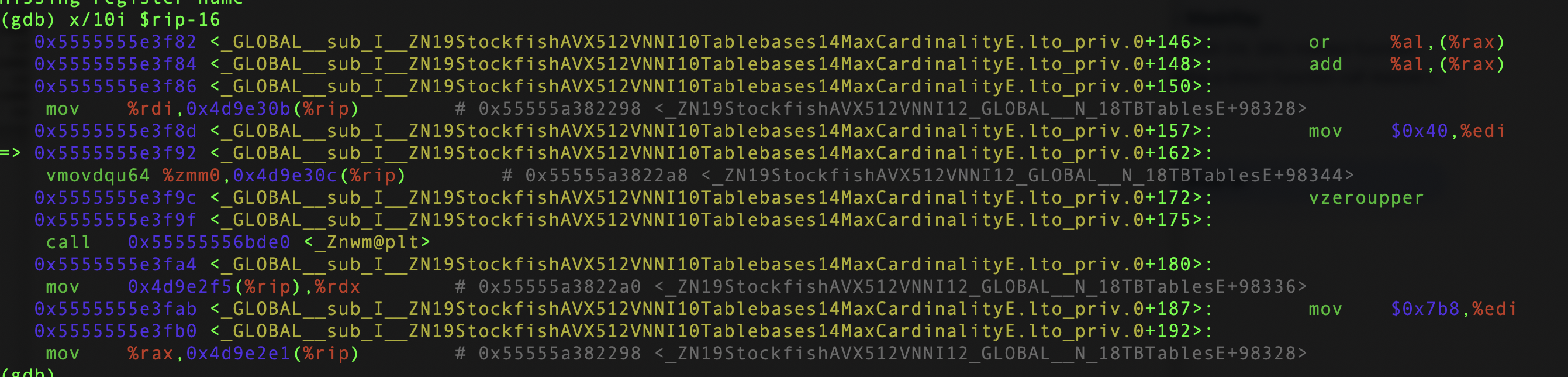
The compiler generated AVX-512 instructions in one of the static initializers (StockfishAVX512VNNI::Tablebases::MaxCardinality), for a build that we won't even use on this AVX2 machine.
My solution was to first combine all object files in a per-arch build into one monolithic stockfish.o, which consolidates the static initializers into a single .init_array or .ctors section. This section is basically just an array of function pointers. We then rename the section with objcopy to a per-arch name like x86_64_avx2_init. When linking to an ELF binary, the beginning and end of this section is accessible in C using the __start_x86_64_avx2_init and __stop_x86_64_avx2_init symbols.
Makefile:
# Rename .init_array (Linux) or .ctors (Windows) so we can manually invoke them
$(OBJCOPY) --rename-section .init_array=$(call arch-suffix,$*)_init $@
$(OBJCOPY) --rename-section .ctors=$(call arch-suffix,$*)_init $@
# Make the array inert
$(OBJCOPY) --set-section-flags $(call arch-suffix,$*)_init=alloc,data $@
entry_x86.cpp:
#define DEFINE_BUILD(x) \
namespace Stockfish_##x { \
extern int main(int argc, char* argv[]); \
} \
extern "C" void (*__start_##x##_init[])(void); \
extern "C" void (*__stop_##x##_init[])(void); \
int entry_##x(int argc, char* argv[]) { \
unsigned count = __stop_##x##_init - __start_##x##_init; \
for (unsigned i = 0; i < count; i++) /* Invoke each initializer */ \
__start_##x##_init[i](); \
return Stockfish_##x::main(argc, argv); \
}
DEFINE_BUILD(x86_64)
DEFINE_BUILD(x86_64_sse41_popcnt)
// ...
With this new setup, we iterate over and call the static initializers ourselves – and only those which are actually needed by the architecture we want. (Some additional shenanigans are necessary on macOS and Windows, but I won't get into that.)
Slow instructions on AMD Zen
AMD chips from Excavator (2015)4 until Zen 3 (2020) implement the bit manipulation instructions pdep and pext in slow microcode. Therefore, they should take the AVX2 codepath (which eschews these instructions) instead of the BMI2 codepath that the cpuid flags would imply:
// AMD Zen/Zen+/Zen2 (family 17h) implement pdep/pext via microcode.
static bool has_slow_bmi2() {
return __builtin_cpu_is("amd")
&& (__builtin_cpu_is("bdver4") || __builtin_cpu_is("znver1") || __builtin_cpu_is("znver2"));
}
// ...
if (!flags.bmi2 || has_slow_bmi2())
return entry_x86_64_avx2(argc, argv);
AVX-512 on macOS
Interestingly, Intel Macs supporting AVX-512 don't set the corresponding bit in xgetbv by default, so __builtin_cpu_supports thinks the OS doesn't support it and we go down a suboptimal code path. When an AVX-512 instruction is executed on such a machine, the OS intercepts the #UD exception, enables AVX-512 for that thread, and re-executes the faulting instruction – see i386/fpu.c. It's only after this handler completes that the AVX-512 bits are set in xgetbv.5
Instead of separate detection code for macOS, I decided to just manually trigger this path in the kernel:
static void maybe_promote_thread_to_avx512() {
#ifdef __APPLE__
int supported = 0;
size_t len = sizeof(supported);
if (sysctlbyname("hw.optional.avx512f", &supported, &len, nullptr, 0) == 0 && supported)
asm volatile(".byte 0x62, 0xf1, 0x7d, 0x48, 0x6f, 0xc0"); // vmovdqa32 zmm0,zmm0
#endif
}
int main(int argc, char* argv[]) {
maybe_promote_thread_to_avx512();
__builtin_cpu_init();
// ...
}
Summary of the global entry point
Implementing link-time optimization (LTO) and profile-guided optimization (PGO)
Stockfish relies on LTO, and to a lesser extent PGO, to achieve peak performance. LTO's benefit mainly comes from cross-TU inlining and interprocedural analysis. PGO allows the compiler to arrange branchy code, especially in search, more intelligently.6
We need to be careful about when we perform LTO: it needs to happen when producing the per-arch object files, but not at the final universal link (since we can only specify baseline flags there, no -mavx2). It gets a little nutty here because getting the intermediate LTOed object is not standardized:
ifeq ($(KERNEL),Darwin)
# Apple uses ld64 which doesn't have --save-temps
LTO_OBJ_SUFFIX := .lto.o
SAVE_TEMPS := -Wl,-object_path_lto,stockfish.lto.o
else ifeq ($(comp), clang)
LTO_OBJ_SUFFIX := .lto.o
ifeq ($(target_windows),yes)
SAVE_TEMPS := -Wl,--lto-emit-asm # ld.lld doesn't have a save temps functionality
use_lto_emit_asm := yes
else
SAVE_TEMPS := -Wl,--save-temps
endif
else
LTO_OBJ_SUFFIX := .ltrans0.ltrans.o
SAVE_TEMPS := -save-temps
endif
And then the later use:
ifeq ($(use_lto_emit_asm),yes)
awk -v MODNAME=$(MODNAME) -f ../../universal/rewrite_asm_sections.awk *.lto.s > renamed.s
$(CXX) -c renamed.s -o stockfish.o $(ASM_FLAGS)
else
cp "$(basename $(EXE))$(LTO_OBJ_SUFFIX)" stockfish.o
endif
The strangest case here, as you can see, is clang on Windows: Instead of getting an object file, all we can reliably extract is the assembly that's going into as. Because of limitations of COFF and llvm-objcopy there's a separate pipeline here for renaming the sections and adding the __start/__stop symbols, that operates directly on this assembly file. Other targets can operate on the stockfish.o object directly.
To be clear, we compile a separate executable for each architecture with LTO, but discard it and just use the intermediate LTOed object.
PGO is a little easier. For each architecture, we compile a binary that will emit feedback and run a standardized workload, potentially under emulation (Intel SDE or QEMU). We then pass the feedback into -fprofile-use, in the same command that produces the LTOed object.
The final link
Now that we have an army – or should I say school? – of stockfish.o LTOed object files, the final (no-LTO) link is straightforward:
ifeq ($(KERNEL),Linux)
UNIVERSAL_FINAL_FLAGS += -static-libstdc++ -static-libgcc
ifeq ($(COMP),ndk) # android
UNIVERSAL_FINAL_FLAGS += -static
else
UNIVERSAL_FINAL_FLAGS += -lrt -lpthread
endif
else ifeq ($(KERNEL),Windows)
UNIVERSAL_FINAL_FLAGS += -Wl,--allow-multiple-definition -static
ifeq ($(COMP),clang)
UNIVERSAL_FINAL_FLAGS += -lpthread
endif
endif
# Baseline build must come first in the final link
ARCH_OBJS := $(TEMP_DIR)/$(BASELINE_ARCH)/stockfish.o \
$(patsubst %,$(TEMP_DIR)/%/stockfish.o,$(filter-out $(BASELINE_ARCH),$(UNIVERSAL_ARCHES)))
$(UNIVERSAL_EXE): $(UNIVERSAL_ENTRY_OBJ) $(NNUE_EMBED_OBJ) $(ARCH_OBJS)
$(CXX) -o $@ $(UNIVERSAL_ENTRY_OBJ) $(NNUE_EMBED_OBJ) $(ARCH_OBJS) $(UNIVERSAL_FINAL_FLAGS)
@echo "Universal binary built: $@"
Notably, there's no -mavx2 or equivalent to be seen, so the output is broadly compatible.
We do need to be careful about the order of the stockfish.o objects to ensure that for genuine collisions (like STL template instantiations), the baseline implementation is selected, or else it might crash. (Stockfish spends almost no time in the STL, so the impact on performance is negligible.)
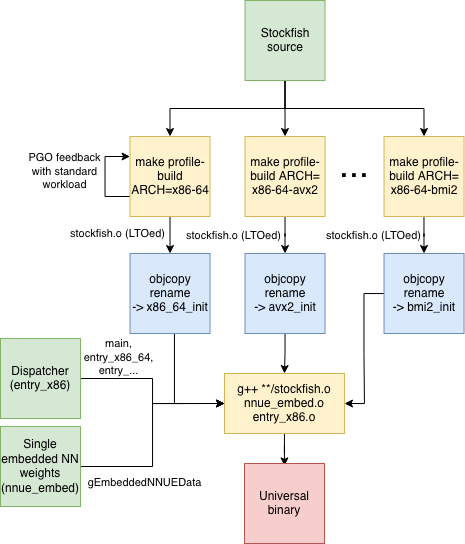
The final process on x64 Linux
macOS universal binary
Strictly speaking, the binaries we've been creating so far are "fat" or "multi-architecture" binaries, rather than Apple's "universal binary" format, which actually includes multiple, completely incompatible ISAs.
Given Intel and Apple silicon builds, creating the universal binary is pretty trivial using the standard lipo utility:
lipo -create stockfish-x86_64 stockfish-arm64 -output stockfish
But this binary will be twice as big as necessary, because there are two identical copies of the neural network. To work around this, we specialize the x86 build to read the NN from the arm64 section. In nnue_embed.cpp:
#ifdef UNIVERSAL_BINARY_MACOS_X86_SLICE
// Must be kept in sync with patch_x86_slice.sh
extern const volatile uint64_t gUniversalNNUEOffset = 0xCAFE0FF5E70FF5E7ULL;
extern const volatile uint64_t gUniversalNNUESize = 0xCAFE512ECAFE512EULL;
static const unsigned char* map_embedded_nnue() {
char path[PATH_MAX];
uint32_t len = sizeof(path);
// get the path to this executable
if (_NSGetExecutablePath(path, &len) != 0)
return nullptr;
char resolved[PATH_MAX];
const char* file = realpath(path, resolved) ? resolved : path;
int fd = open(file, O_RDONLY);
if (fd < 0)
return nullptr;
// Align down to page size for mmap
const uint64_t pageSize = uint64_t(sysconf(_SC_PAGESIZE));
const uint64_t base = gUniversalNNUEOffset & ~(pageSize - 1);
const uint64_t pad = gUniversalNNUEOffset - base;
// Map in the network weights
void* p = mmap(nullptr, size_t(gUniversalNNUESize + pad), PROT_READ, MAP_PRIVATE, fd, off_t(base));
close(fd);
if (p == MAP_FAILED)
return nullptr;
return reinterpret_cast<const unsigned char*>(p) + pad;
}
extern const unsigned char* const gEmbeddedNNUEData = map_embedded_nnue();
extern const unsigned int gEmbeddedNNUESize = (unsigned int) gUniversalNNUESize;
#endif
The gUniversalNNUEOffset and gUniversalNNUESize variables are assigned magic values, and a brutish script patch_x86_slice.sh replaces them with the actual offset and size of the binary.
To be honest, this part of the universal binary project is what I'm least fond of: it's nontrivial to implement, Intel Macs (while not uncommon) are going the way of the dodo, and the x86 slice could probably break down in some situations (e.g., if you strip the binary, or maybe some bad interaction with code signing). But it works fine for the common use case of downloading Stockfish to run in your favorite GUI, and I trust that macOS app developers can independently ship the (perfectly functional) apple-silicon and x86-64-universal builds if necessary.
Some closing remarks
So that's it! We went from twenty-seven official binaries to just seven:
This project was way less linear than I just described, with numerous dead ends, hopelessly broken binaries, and even GCC bugs. But I'm quite happy with how it turned out.
I'm curious how a similar construction for a Rust chess engine would look. I imagine that you could do most of the hard work in LLVM IR.
Shout out to vondele and Disservin for their help and (as project leaders) openness to substantially changing how we ship our work. Hopefully the collective time saved from faster analysis will exceed the hours I invested into this project. 🥴
AI disclosure
Generative AI was not used in the creation of this blog post – cope and seethe.
Footnotes
For x86-64 Windows, our largest user base, we advertised the AVX2 binary. In practice, the delta between the AVX2 and AVX-512 binaries on recent systems supporting both is smaller, around 20%; but that's still a nontrivial time savings. ↩
I tried the simpler method of just using a C array from
xxd, but the compiler would always run out of memory – I assume while constructing the AST.#embedhas the same semantics but is special cased in the compiler. And of course, a string literal consists of one (giant) token. ↩Probably 256-bit SVE only, as 128-bit SVE is pretty much useless to us. ↩
In my original PR I only included Zen/Zen+/Zen2, but ciekce pointed out that AMD Excavator is also affected. ↩
I guess the idea here is because most programs don't use AVX-512, the kernel usually doesn't have to save the additional state, but this is definitely not compliant with Intel's recommendations.... ↩
We find that PGO helps GCC a lot more than clang, although we support PGO on both. The latest versions of GCC and clang are essentially neck-and-neck on performance, although on my system GCC 16 pulls ahead by a consistent ≈1%. ↩